多様体学習
次元削減に利用できる手法として主成分分析がある。これは柔軟であり、すぐに実装可能な次元削減アルゴリズムの一つである。しかし一つだけ問題がある。それは主成分分析に適用できるデータは線形のみであり、非線形のデータには利用できない。非線形データの次元削減に利用できるのが多様体学習(Manifold Learning)である。主成分分析と多様体学習の関係はいうなれば線形回帰と非線形回帰の関係である。
ではこの次元圧縮はどのようなイメージになるのだろうか。主成分分析で3次元データを2次元データに圧縮することを考える。この場合3次元空間に平らな紙を一枚置いてすべてのデータをこの平らな紙に移したと考えることができる。紙は平らなだから2次元である。これにより3次元データは2次元に圧縮された。多様体学習もイメージは似ている。しかし多様体学習ではこの紙は丸まったり曲がったりしてより柔軟(非線形)にデータを移すことができる。これが主成分分析と多様体学習の違いである。
主成分分析では軸を回転させることで最も分散が大きい成分を見つけることができた。これはデータが線形であったから可能である。しかしデータが非線形であれば事情は異なる。データを回転させる、引き伸ばす、方向を変えるといった操作では、3次元におけるデータの位置関係は変わらない。これは線形な操作であり、非線形データにとって最も大きな分散となる軸を探すことができない。多様体学習では折り曲げ、ロール、崩すなどといった操作により最も大きな分散となる軸を探すことになる。
距離行列
距離行列とはある要素のベクトルと他の要素のベクトルの距離(あるいは類似度)を行列であらわしたものである。
生成したHello画像同士について距離行列を見てみると以下のようになる。これは同じ画像であるから対角線の軸は当然0(距離が0あるいは完全一致)となる。
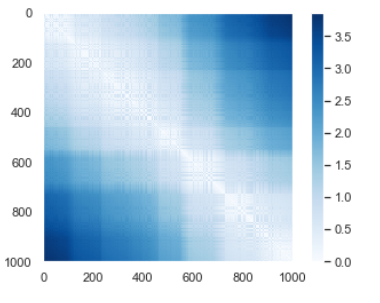
次に回転させたHello画像との距離行列をみてみる。全く変わらないことから回転では類似度に変化はない。

MDSによる距離行列からのデータ復元
MDS(Multi Dimensional Scaling)により距離行列からデータを復元する。さてこのデータは生成したデータと同じになるのだろうか。
from sklearn.manifold import MDS
model = MDS(n_components=2, dissimilarity='precomputed', random_state=1)
out = model.fit_transform(D)
plt.scatter(out[:, 0], out[:, 1], **colorize)
plt.axis('equal');
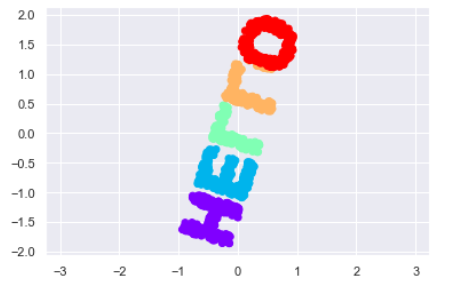
復元されたデータは距離行列から取得できる一つの例である。Lが両方とも逆になっているのがわかる。また回転もしている。
多様体学習としてのMDS
MDSは多様体学習のアルゴリズムとして非線形データについて次元削減ができる。これは以下のような手順による
多次元データ→距離行列の作成→距離行列にあった2次元平面の生成
非線形平面への投影にはMDSを用いることはできない。その場合にはLLE(Locally Linear Embedding)を利用する。難しくて理解できないのこちらはパス。
