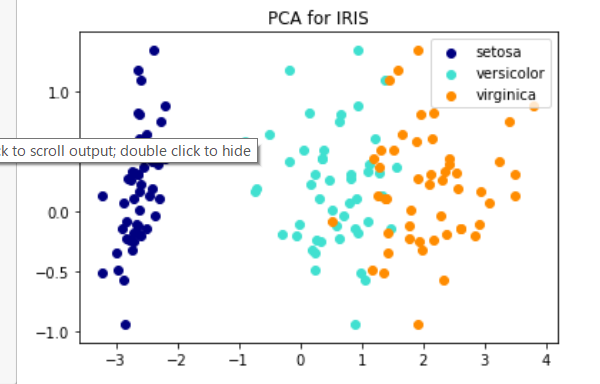
irisデータをPCAで2次元に分類して可視化してみる。
内容
- 準備及びデータの前処理
- PCA
- プロット
準備及びデータの前処理
irisデータを読み込み、PCAを実行するための前処理をする。ここの詳細については、
を参照
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import numpy as np
# データセット読み込み
iris = sns.load_dataset('iris')
# データ前処理
X_iris = iris.drop('species', axis=1)
PCA
PCAはsklearn.decomposition.PCAを用いる。
class sklearn.decomposition.PCA(n_components=None, copy=True, whiten=False, svd_solver=’auto’, tol=0.0, iterated_power=’auto’, random_state=None)
| n_components | PCAの主成分の数 |
# PCA pca = PCA(n_components=2) pca.fit(X_iris) pca_transformed = pca.transform(X_iris)
プロット
PCAで算出した主成分1および2の値はpca_transformedに格納されている。
print(pca_transformed) # [[-2.68412563 0.31939725] [-2.71414169 -0.17700123] [-2.88899057 -0.14494943] [-2.74534286 -0.31829898] [-2.72871654 0.32675451]
プロットするためにこの値をirisデータにマージする。
# データマージ iris["PCA1"] = pca_transformed[:, 0] iris["PCA2"] = pca_transformed[:, 1]
プロットするにあたり種別で色を指定したいために、種別と色を設定した配列を作成する。
# プロット species = y_test.unique() print(species) #['setosa' 'versicolor' 'virginica'] colors = ['navy', 'turquoise', 'darkorange']
このデータを種別に読み込みながらプロットする。
for color,label in zip(colors, species):
plt.scatter(iris[iris["species"]==label]["PCA1"],iris[iris["species"]=="setosa"]["PCA2"], color=color, label=label)
plt.title("PCA for IRIS")
plt.legend(loc="best")