Kaggle TitanicのFareを使っていくつかビジュアル
金額別ヒストグラム-1
-
titanic_df['Fare'].plot(kind='hist', figsize=(15,3),bins=100, xlim=(0,50))
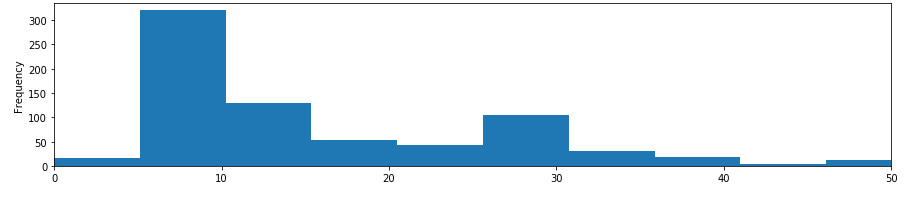
xlimが簡単に設定できる
金額別ヒストグラム-2
- sns.distplot(d_train[“Fare”], kde=False, rug=False, bins=100)

xlimは軸で設定するのでひと手間かかる
生存別金額-1
- avgerage_fare = pd.DataFrame([fare_not_survived.mean(), fare_survived.mean()])
- std_fare = pd.DataFrame([fare_not_survived.std(), fare_survived.std()])
- avgerage_fare.plot(yerr=std_fare,kind=’bar’,legend=False)
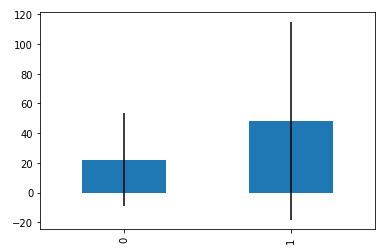
みやすい。
生存別金額-2
- sns.boxplot(x=’Survived’, y=”Fare”, data=d_train, palette=”PRGn”)
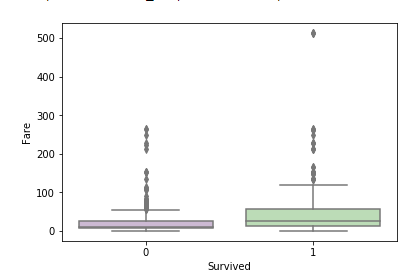
外れ値に左右される→外れ値を削除する。
生存別金額-3
- sns.violinplot(x=’Survived’, y=”Fare”, data=d_train)
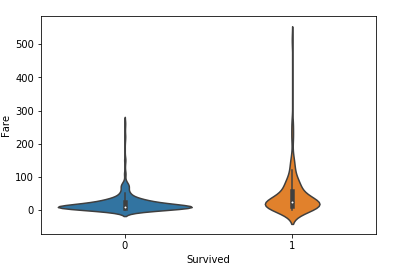
概要をつかむにはboxplotよりよい。
