いろいろ試しているがうまくいかないので、とりあえずAgeを正しく補完できるか調べる。
調査は線形回帰でどれくらい相関が出るかで判断する。
import numpy as nm
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
d_train = pd.read_csv('train.csv')
d_test = pd.read_csv('test.csv')
d_train['FamilySize'] = d_train['SibSp'] + d_train['Parch'] + 1
d_test['FamilySize'] = d_test['SibSp'] + d_test['Parch'] + 1
dummies_titanic = pd.get_dummies(d_train['Sex'])
dummies_titanic.columns = ['Female','Male']
d_train = d_train.join(dummies_titanic)
dummies_titanic = pd.get_dummies(d_test['Sex'])
dummies_titanic.columns = ['Female','Male']
d_test = d_test.join(dummies_titanic)
d_train["Embarked"] = d_train["Embarked"].fillna("S")
dummies_titanic = pd.get_dummies(d_train['Embarked'])
dummies_titanic.columns = ['E0','E1', 'E2']
d_train = d_train.join(dummies_titanic)
dummies_titanic = pd.get_dummies(d_test['Embarked'])
dummies_titanic.columns = ['E0','E1', 'E2']
d_test = d_test.join(dummies_titanic)
dummies_titanic = pd.get_dummies(d_train['Pclass'])
dummies_titanic.columns = ['Class_1','Class_2', 'Class_3']
d_train = d_train.join(dummies_titanic)
dummies_titanic = pd.get_dummies(d_test['Pclass'])
dummies_titanic.columns = ['Class_1','Class_2', 'Class_3']
d_test = d_test.join(dummies_titanic)
d_test["Fare"] = d_test["Fare"].fillna(35.6271884892086)
d_train = d_train.drop(['PassengerId','Survived', 'Sex', 'Name','Ticket','Cabin', 'Parch','SibSp', 'Embarked', 'Pclass'], axis=1)
d_train.dropna(subset=['Age'])
X = d_train.drop("Age", axis=1).copy().as_matrix()
Y = d_train["Age"]
from statsmodels import api as sm
model = sm.OLS(Y, sm.add_constant(X))
result = model.fit()
result.summary()
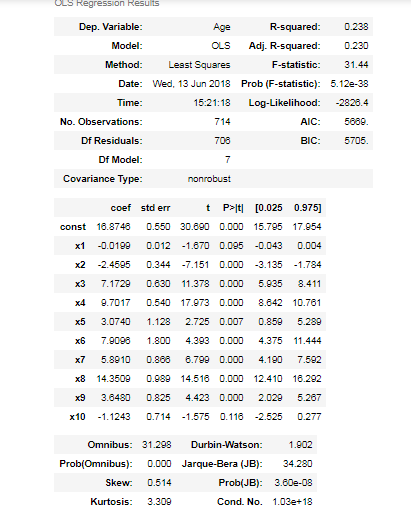
結論としてはAgeをうまく埋める方法はないらしい。こうなってしまっては適当にランダムデータで埋めて、学習に影響が出ないようにする。
