Rによるクラスタ分析の実行
県別の持家率と自家用車普及率からクラスタ分析を実行し似た県を探してみる。。
データソース
csv
データをcsvにまとめる。
pref,home,car 愛知県,.5784,.513 愛媛県,.6561,.474 茨城県,.7073,.66 岡山県,.6653,.644 沖縄県,.5016,.417 岩手県,.7194,.603 岐阜県,.7386,.673
データ読み込み
csvデータをRに読み込む
> data <- read.csv("data.csv", row.names=1)
> head(data)
home car
愛知県 0.5784 0.513
愛媛県 0.6561 0.474
茨城県 0.7073 0.660
岡山県 0.6653 0.644
沖縄県 0.5016 0.417
岩手県 0.7194 0.603
Rで読み込む際に県データを行名にする(row.names=1)。これによりクラスタリング実行時に各データが県で表示される。実施しないと行番号になるために識別が難しい。
距離計算
各要素の距離をdist()でもとめる。
> data.d <- dist(data) 警告メッセージ: In dist(data) : 強制変換により NA が生成されました > data.d 1 2 3 4 5 6 2 0.106477392 3 0.239450026 0.236275602 4 0.192532893 0.208511295 0.055045436 5 0.150570117 0.201690047 0.389925935 0.342768194 6 0.204869471 0.175988167 0.071366063 0.083136725 0.350783780 7 0.277301388 0.263838729 0.041509457 0.096544472 0.427267481 0.088898594 8 0.167743375 0.182549486 0.073548861 0.026526119 0.318260648 0.076762882 9 0.040435319 0.066066330 0.231480021 0.190816666 0.164813030 0.186383516 10 0.331404941 0.287860800 0.523893348 0.494951149 0.248554451 0.460474576 11 0.101566431 0.112600688 0.140496388 0.100535740 0.250692920 0.104505694 12 0.298463465 0.307669002 0.073485611 0.106171253 0.448327157 0.144097675 13 0.111718016 0.078471269 0.307412524 0.272627328 0.135272004 0.251795780 14 0.206386773 0.189205801 0.050280364 0.062086351 0.354932754 0.023108440 15 0.109499041 0.051042482 0.185241397 0.159246272 0.235684450 0.125997381 16 0.222379271 0.224989633 0.019219131 0.035838178 0.372947262 0.070447427 17 0.294935374 0.232734527 0.465298872 0.441169627 0.246720561 0.399092564 18 0.261973043 0.249639059 0.028109429 0.082823547 0.411940329 0.075808146 19 0.318428862 0.306533090 0.079299275 0.131967326 0.468741784 0.131077229
クラスタ分析の実行
クラスタ計算をする。
> data.hc <- hclust(data.d)
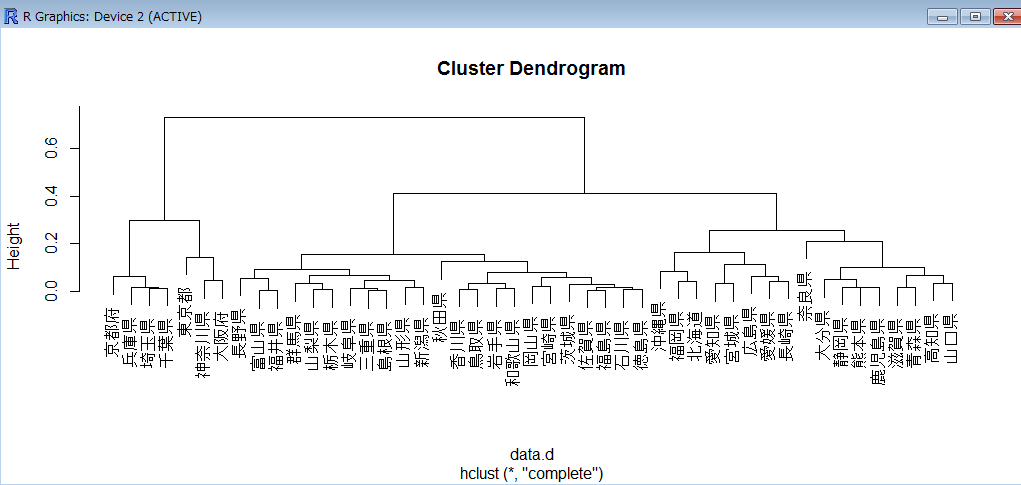
デンドログラム
デンドログラムを描く
> plot(data.hc)