rvestで対象とするhtmlのブロックは下記のように取得できる。
http://blog.rstudio.com/2014/11/24/rvest-easy-web-scraping-with-r/
<span class="hljs-keyword">library</span>(rvest) lego_movie <- html(<span class="hljs-string">"http://www.imdb.com/title/tt1490017/"</span>) lego_movie %>% html_node(<span class="hljs-string">"strong span"</span>) %>% html_text()
この時に問題になるのがどうやってnode “strong span”を見つけるかである。
見つける方法としては2つある。一つ目はgoogle developer toolsを利用する。
- 開いたページで目的とする個所を選ぶ→ここで右クリック→inspectを選ぶ。
- これで該当箇所のhtmlスクリプトが開く。
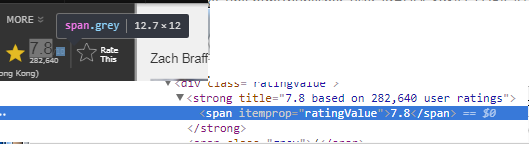
- 次に対象項目を囲んでいるタグを2つ取得。
- html_node()を実行してみる。もし予想した値が返っていない場合にはタグが2つでは絞り込みができていない。その場合にはタグを順番に増やしてあげる。
2つ目の方法としてはSelectorGadgetを利用する。これは項目のすぐ上の階層についてはcssセレクタが取得できる。selectorGadgetについては下記で詳細に説明している。
またセレクタはタグ、class、idにより表記方法が変わる
- class : .クラス名
- id : #ID名
- タグ : タグ名
表記方法についてはこちらから参照できる。
