分散分析についてcase studyをしてみる。目的はRで分散分析を実行する際の手順を明確にすること、およびそれに付随するRの関数を理解することである。
目標として以下をあげておく
- テストデータを含めた操作をすべてRで完結させる
- グラフィックをRで作成する
- 分散分析を行う
まず一般的な手順を明らかにしておく
- データをRに読み込む
- クレンジング
- データを理解する
- 統計的分析を行う
- 考察する
まずデータを作成する。今回は以下のシナリオに基づく。
Networkパフォーマンスをスピードであらわす。スピードは大きいほどよい。このスピードに与える3要因について評価する。
- 要因1: ルータ
- 要因2: スイッチ
- 要因3: ケーブル
要因1のルータでは2つの異なったルータを用意する。それぞれR1, R2とする。性能はR1>R2とする。要因2のスイッチも2つの異なったスイッチとする。それぞれS1, S2とする。性能はS2>S1とする。ケーブルもC1, C2とする。ケーブルに関しては性能に与える影響は同等とする。
上記の仮定に基づき、テストデータを作成する。
テストデータ作成は以下のように進める。
- スイッチのspeedの平均値のみ決める。S1 は80, S2は150とする。
- この平均値を基にして正規分布表からランダムにデータを取り出す。
- 取り出した値について大きいほうをR1、小さいほうをR2に割り当てる。
- 割り当てた値を平均として小さい分散でランダム値を2つ作る。これをケーブルC1, C2に割り当てる。
rnorme <- function(n, mean, sd){
w_norm <- rnorm(n-1, mean=mean, sd=sd)
w_norm <- c(w_norm, mean * n - sum(w_norm))
return (w_norm)
}
s1 <- rnorme(2,80,20)
s1 <- sort(s1, decreasing=TRUE)
s1
s1 <- lapply(s1, function(x) rnorme(2,x,5))
s1
s1 <-unlist(s1)
s1
s2 <- rnorme(2,150,20)
s2 <- sort(s2, decreasing=TRUE)
s2
s2 <- lapply(s2, function(x) rnorme(2,x,10))
s2
s2 <- unlist(s2)
s2
以下が実行内容
> s1 <- rnorme(2,80,20) > s1 <- sort(s1, decreasing=TRUE) > s1 [1] 99.31832 60.68168 > s1 <- lapply(s1, function(x) rnorme(2,x,5)) > s1 [[1]] [1] 92.90066 105.73599 [[2]] [1] 60.81789 60.54547 > s1 <-unlist(s1) > s1 [1] 92.90066 105.73599 60.81789 60.54547 > > > s2 <- rnorme(2,150,20) > s2 <- sort(s2, decreasing=TRUE) > s2 [1] 163.5751 136.4249 > s2 <- lapply(s2, function(x) rnorme(2,x,10)) > s2 [[1]] [1] 174.6611 152.4891 [[2]] [1] 151.6649 121.1849 > s2 <-unlist(s2) > s2 [1] 174.6611 152.4891 151.6649 121.1849
このデータはフラットなのでデータの解析をするにしてもanovaを実行にするにしても不便であるのでdata.frameに変換する。
type_router <- c(rep("r1",4),rep("r2",4))
type_router
type_switch <- rep(c(rep("s1",2),rep("s2",2)),2)
type_switch
type_cable <- rep(c("c1","c2"),4)
type_cable
speed <- c(s1[1:2], s2[1:2], s1[3:4], s2[3:4])
speed
speed_test <- data.frame(router=type_router, switch=type_switch, cable=type_cable, speed=speed)
speed_test
下記は実行した内容
> type_router <- c(rep("r1",4),rep("r2",4))
> type_router
[1] "r1" "r1" "r1" "r1" "r2" "r2" "r2" "r2"
> type_switch <- rep(c(rep("s1",2),rep("s2",2)),2)
> type_switch
[1] "s1" "s1" "s2" "s2" "s1" "s1" "s2" "s2"
> type_cable <- rep(c("c1","c2"),4)
> type_cable
[1] "c1" "c2" "c1" "c2" "c1" "c2" "c1" "c2"
> speed <- c(s1[1:2], s2[1:2], s1[3:4], s2[3:4])
> speed
[1] 92.90066 105.73599 174.66112 152.48912 60.81789 60.54547 151.66489
[8] 121.18488
>
> speed_test <- data.frame(router=type_router, switch=type_switch, cable=type_cable, speed=speed)
> speed_test
router switch cable speed
1 r1 s1 c1 92.90066
2 r1 s1 c2 105.73599
3 r1 s2 c1 174.66112
4 r1 s2 c2 152.48912
5 r2 s1 c1 60.81789
6 r2 s1 c2 60.54547
7 r2 s2 c1 151.66489
8 r2 s2 c2 121.18488
傾向を調べるために2変数で傾向を調べる。まず2変数でまとめたテーブルを作成する。
agg_rs <- aggregate(speed_test$speed, speed_test[,c("router","switch")], mean)
colnames(agg_rs) <- c("router", "switch", "speed")
agg_rc <- aggregate(speed_test$speed, speed_test[,c("router","cable")], mean)
colnames(agg_rc) <- c("router", "cable", "speed")
agg_sc <- aggregate(speed_test$speed, speed_test[,c("switch","cable")], mean)
colnames(agg_sc) <- c("switch", "cable", "speed")
agg_rs
agg_rc
agg_sc
それぞれのテーブルは以下のようになる。
> agg_rs router switch speed 1 r1 s1 99.31832 2 r2 s1 60.68168 3 r1 s2 163.57512 4 r2 s2 136.42488 > agg_rc router cable speed 1 r1 c1 133.78089 2 r2 c1 106.24139 3 r1 c2 129.11255 4 r2 c2 90.86517 > agg_sc switch cable speed 1 s1 c1 76.85927 2 s2 c1 163.16300 3 s1 c2 83.14073 4 s2 c2 136.83700
テーブルだけ見てもよくわからないので要因効果図を作成してみる。
library(ggplot2)
g_rs <- ggplot(agg_rs, aes(x=router, y=speed, group=switch, color=switch)) + geom_line() + geom_point(size=3) + ylim(0,200)
g_rc <- ggplot(agg_rc, aes(x=router, y=speed, group=cable, color=cable)) + geom_line() + geom_point(size=3) + ylim(0,200)
g_sc <- ggplot(agg_sc, aes(x=switch, y=speed, group=cable, color=cable)) + geom_line() + geom_point(size=3) + ylim(0,200)
require(gridExtra)
grid.arrange(g_rs, g_rc, g_sc, main=textGrob("Compare performance between three factos(router, switch and cable)", gp=gpar(cex=1)), ncol=3)
プロット結果は以下のようになった。
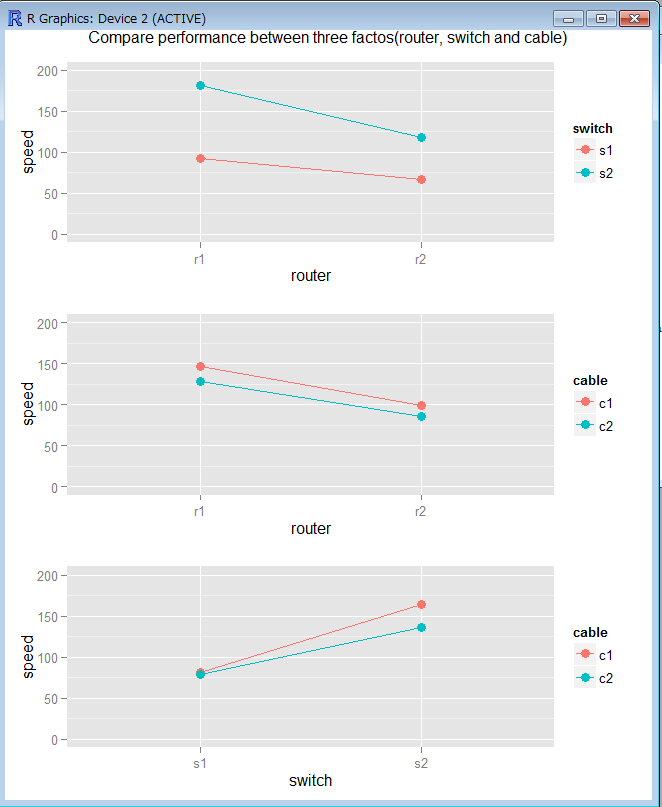
この結果を分析してみる。
図1よりR1とR2を比較するとスピードはR1のほうが常に上である。またS1とS2ではS2のほうがよい。交互作用は見られない。図2からR1 > R2である。ケーブルの違いによるSpeedへの影響は見られない。図3からS2>S1である。ケーブルの違いによるSpeedへの影響は見られない。
