KaggleでTitanic tutorialにチャレンジしてみる。
Titanic: Machine Learning from Disaster
https://www.kaggle.com/c/titanic
ライブラリ読み込み
import numpy as nm import pandas as pd import seaborn as sns %matplotlib inline
データの読み込み
d_train = pd.read_csv('train.csv')
d_test = pd.read_csv('test.csv')
データの確認
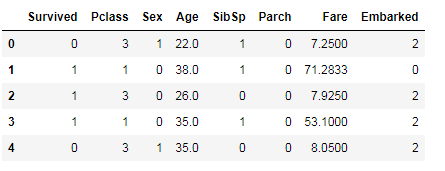
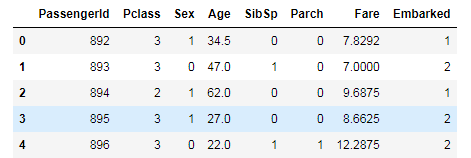
d_train.head() d_test.head()


トレーニングデータに存在して、テストデータに存在しない項目があるか確認する。このような項目は分析には使えないので削除対象となる。今回は特にそのような項目はない。
次に使えなさそうなデータを見てみる。PasssengerID, Name, Ticketは役に立たなさそうなのでドロップ対象とする。
nullがある項目としては明らかなのはCabin。それ以外にもあるかもしれないので確認する。
レコード数を確認する。
d_train.shape
(891, 12)
d_test.shape
(418, 11)
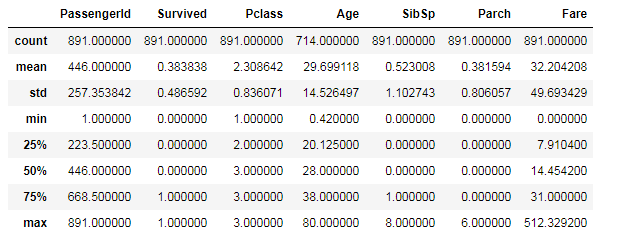
データの基本統計量を確認する。
d_train.desribe()
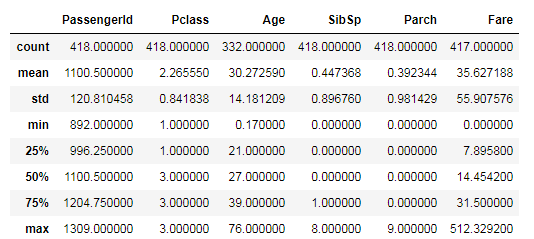
d_test.describe()
欠損値の概要を見てみる。
sns.heatmap(d_train.isnull(),yticklabels=False,cbar=False,cmap='viridis')
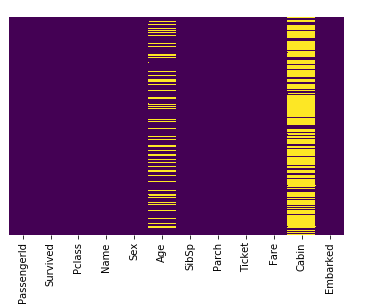
有効データ数を確認
d_train.count()
PassengerId 891
Survived 891
Pclass 891
Name 891
Sex 891
Age 714
SibSp 891
Parch 891
Ticket 891
Fare 891
Cabin 204
Embarked 889
dtype: int64
無効なデータを確認
d_train.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
Testデータも同様に確認
d_test.count()
PassengerId 418
Pclass 418
Name 418
Sex 418
Age 332
SibSp 418
Parch 418
Ticket 418
Fare 417
Cabin 91
Embarked 418
dtype: int64
d_test.isnull.sum()
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64
欠損値に対する方向性を確認する。Age,Embarked,Fareは保管する、Cabinは欠損値が多いので削除。
不要の項目を削除する。
d_train = d_train.drop(['PassengerId','Name','Ticket','Cabin'], axis=1) d_test = d_test.drop(['Name','Ticket','Cabin'], axis=1) d_train.head() d_test.head()
Embarkedを埋める。Embarkedはカテゴラルデータであり、2件だけ欠損している。最頻値を利用する。
pd.value_counts(d_train['Embarked'])
S 644
C 168
Q 77
Name: Embarked, dtype: int64
d_train["Embarked"] = d_train["Embarked"].fillna("S")
次にFareを保管する。Fareは連続値なのでとりあえず中央値を利用する。
d_test['Fare'].mean() 35.6271884892086 d_test["Fare"] = d_test["Fare"].fillna(35.6271884892086)
Ageも連続値なので中央値を利用する。
d_train['Age'].mean() d_train["Age"] = d_train["Age"].fillna(29.69911764705882) d_test['Age'].mean() d_test["Age"] = d_test["Age"].fillna(30.272590361445783)
最後に文字列であるカテゴラルデータを数値に変換する。
from sklearn.preprocessing import LabelEncoder LE=LabelEncoder() labels = ['Embarked','Sex'] for label in labels: d_train[label]=LE.fit_transform(d_train[label]) d_test[label]=LE.fit_transform(d_test[label])
データクレンジングの結果を確認する。
d_train.head() d_test.head()