3.1 Types of Unsupervised Learning
教師なし学習の例
- 次元削減: 重要な特徴量のみを使って元のデータを表現する
- トピック抽出: データを構成する部品を見つける
- クラスタリング: 似たデータをグループに分類する
3.2 Challenges in Unsupervised Learning
正解ラベルがないために、モデルの正しさを評価しにくい。
- データ探索のために用いられる
- 教師あり学習の準備のために用いられる。
3.3 Preprocessing and Scaling
Scalerの種類
- StandardScaler: 平均=0、分散=1とする。しかし最小値と最大値の取り扱いについては問題が残る。極端に大きな外れ値が存在する場合には、意図しているスケーリングに対してずれが生じる。
- RobustScaler: 外れ値の影響を小さくする。
- MinMaxScaler: すべてのデータを0~1に収める
- Normalizer: 円状にスケーリングする。データの方向性が問題になる場合に有効
Scalingする時の注意
- 学習データと検証データについてそれぞれScalerを作成する。
- 学習データのScalerを検証データに用いると、Scalingがおかしくなる
3.4 Dimensionality Reduction, Feature Extraction, and Manifold Learning
Feature, Correlation
the direction along which the features are most correlated with each other.
- Correlation : 日本語では相関、ちなみに変数の係数もcorrelationという。本質としては同じ意味になるある変数の変化に対して、別の変数がどの程度変化するか。もし全く変化が関係名なら相関係数は0に近くなる。それに対して比例で変化するならばCorrelationは1に近づき、さらに係数としてのCorrelationも算出される。
3.4.1 Principal Component Analysis (PCA)
PCAとGray Scaleを組み合わせる
mglearn.plots.plot_pca_whitening()
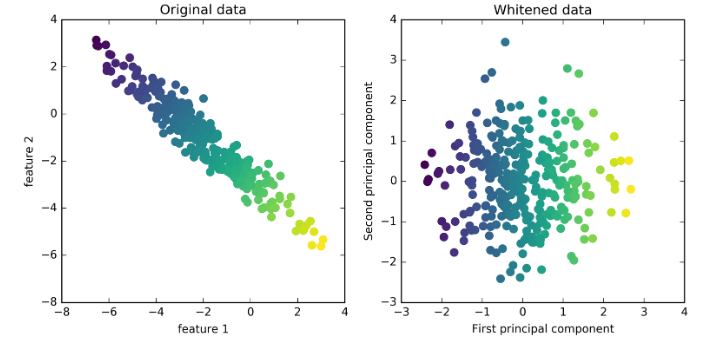
- PCAのみでは散布図は楕円形になるので縦方向に対する解像度はよくない。しかしグレースケールを組み合わせると形状は円状になるためにすべての方向について分類の正解度が上がる。
- PCAでグレースケールを利用するにはPCAでwhiten=Trueを設定する
pca = PCA(n_components=100, whiten=True, random_state=0).fit(X_train)
PCAの第一および第二主成分のみで分類ができるかを確認する
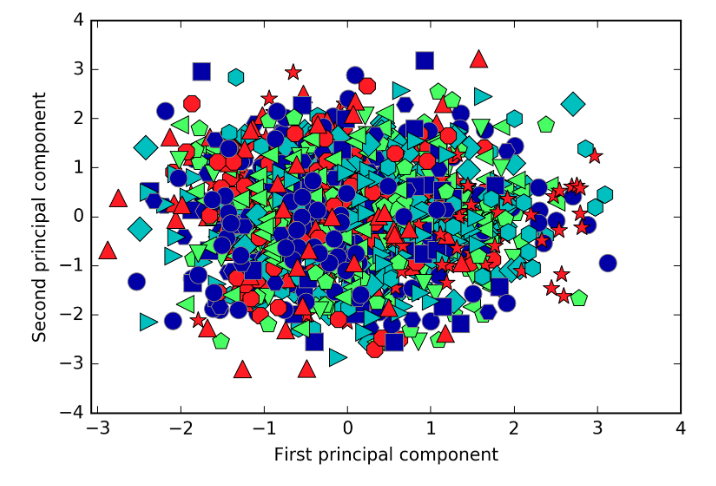
同じマーク、例えば赤の▲は同じ人物を表す。マークがある特定の位置に固まっていれば第一および第二主成分で分類可能といえる。しかし実際に見てみるとどのマークも円状に分散している。これは第一および第二主成分のみでは人物の識別が難しいことを意味する。実際に第一および第二主成分のみで画像を復元してみると、視覚上、識別は困難である。
3.4.2 Non-Negative Matrix Factorization (NMF)
NMFはPCAと考え方は同じである。違う点は、係数はすべての0以上になる。よって結果も0以上になる。
NMFでは各成分は負にならないために、分解した成分は足しあわされるだけになる。足しすぎると負の計算で元に戻ることができないために各成分はスパースになることが予想される。
3.4.3 Manifold Learning with t-SNE
多様体学習
- 画像データの分析
- PCAとおなじで次元を減らす
- 学習データのみに適用できる。テストデータには適用できない。よって探索的データ分析には有効といえる。
3.5 Clustering
3.5.1 k-Means Clustering
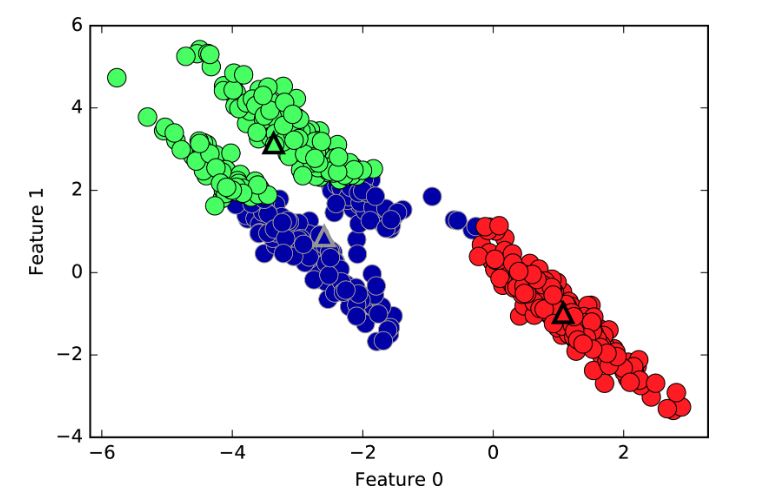
k-Meansの特徴
- クラスタの中心は等高線、おなじ直径を仮定している
- クラスタはすべての方向に次いで同じ程度に重要である。
- クラスタの形状によっては想定外の結果を招く
- 例としては楕円形のクラスタがある
ベクトル量子化
- 量子化=値を最も近い不連続の値にマッピングする
- ベクトル量子化=ベクトルを代表ベクトルに近似する
- https://www.slideshare.net/miyoshiyuya/9
kmeans, pca, nmfの比較
- kmeansは代表ベクトルになる。そのクラスタの平均化した顔
- pcaおよびnmfはどうなるのか?
two_moonクラスタリングの分析
- PCAおよびNMFによる分析はできることが少ない。次元を減らすと各データポイントの判別はつかなくなる
- k-meansではクラスタ数を増やすことにより、結果として2つのクラスタを分けることができる。
3.5.2 Agglomerative Clustering
クラスタのマージ方法
- ward : デフォルト、クラスタの分散が最小になるようにマージする。同じサイズのクラスタに落ちつく傾向がある
- average : すべてのデータポイントについて最も平均距離が短いクラスタをマージ
- complete : 最長距離が最も短いクラスタをマージ
マージ方法の選択
- 基本はwardを利用する
- クラスタに大きな偏りがある場合には、average もしくは completeを利用する
ヒエラルキー
- クラスタリングは小さいグループを繰り返し集める。
- これによりヒエラルキーが構成される
- ヒエラルキーは等高線もしくはデンドログラムにより表現できる
非線形に対応できるか
- ある程度は可能であるが、two moonは難しい
- DBSCANでは可能である
3.5.3 DBSCAN
core samples
- ランダムポイントを選ぶ
- eps距離内に最低min_samples個のデータがある場合、このデータポイントはcore sampleとしてラベル付けされる
- eps距離よりも近いcore sampleはおなじクラスタとして取り扱う
- eps距離内にmin_samples個のデータがない場合には、この範囲のポイントはnoiseとして取り扱われる。
- noiseはいづれのクラスタにも属さない
- eps内のラベル付けが完了すると次のポイントが選ばれ、同じ処理を繰り返す
- 最終的にはすべてのテンは, core point, eps内のcore point ( boundary point ) 、noiseに分類される
Hyper parameter
- epsこの値を増やすとクラスタが大きくなる。ただし大きくしすぎると異なったクラスタを結合してしまう可能性がある
- min_samples : この値を増やすとcore pointが少なくなり、noiseが多くなる
eps
- このパラメータが最重要である。なぜならポイントが”近い”という概念を決めるからである。
- epsが小さいとcore pointがないためにほとんどのポイントがnoiseになる。
- epsが大きすぎるとシングルクラスタになる。
min_samples
- このパラメータにより密度が低い場所にあるポイントが外れ値として取り扱われるか、もしくはクラスタを構成するか決める
- min_samplesを増やせば、noiseとして取り扱われる可能性が高くなる。
- min_sampleはクラスタの最低構成数を決める
3.5.4 Comparing and Evaluating Clustering Algorithms
クラスタリングアルゴリズムを評価する指標
- ARI (adjusted rand index)
- NMI (normalized mutual information)
クラスタのメトリック
- accuracy_scoreは使わない
- adjusted_rand_score, normalize_mutual_info_scoreを用いる
- clusters1および2は正解率では0になる。これはお互いの要素がすべて異なっている値のためである。
- しかしクラスタにとってラベルは意味がない。両方のクラスタで要素1,2,5と要素3,4はおなじクラスタに分類されている。このためARIとしては1.0になる。
clusters1 = [0, 0, 1, 1, 0] clusters2 = [1, 1, 0, 0, 1]
その他のメトリック
- ARIおよびNMIはもとになる比較できる正解が必要である。しかし実際にはクラスタリングでは正解データは用意されていない。また用意されているのであれば教師付き学習を利用すればよい。
- 一つの方法としてシルエット係数がある。しかし実際に利用すると高いスコアでも予想とは違うクラスタ形状になるためにあまり利用されてない。
- 別の方法としては頑健性クラスタリングメトリックがある。これはデータにノイズを混ぜる、パラメータを変更して結果を比較する。同じ結果が出ればモデルは信頼性が高いといえる。
epsとクラスタの関係
- eps=7でクラスタ数は最大の9となる。
- しかし実際にクラスタのポイント数を見ると極端に大きなサイズのクラスタ(1527)が一つと、それ以外となる。
- これはほとんどのイメージが同じように見えるということを意味する
eps=7 Number of clusters: 9 Cluster sizes: [1527 15 3 3 5 14 3 3 4]
Face recognition
- DBSCANでは一つの大きなクラスタが認識された→顔の検出はうまくいっていない
- k-meansは比較的同じサイズのクラスタを生成した。この違いはnoiseがあるかどうかである。クラスタを増やせば、より詳細な認識ができるが、説明が難しくなる。
- ARIをk-meansとagglomerativeで比べると10%程度になる→クラスタリングアルゴリズムによりデータポイントのラベル付けは変わってくる。
