幾何平均が値付けに利用されているという話を聞いたので実際の商品を例にして分析してみる。
調査の目的
適切なダウンジャケットを選ぶことで冬季にあるいは夏季の3000m級の高山で気持ちよく過ご巣ことができる、またシュラフの変わりになるために軽量化を図ることができる。しかし質がよいダウンジャケットになるほど価格も格段に跳ね上がってしまう。現在ではメーカーによる研究も充実し、平均名山行をベンチマークとして、売れ筋のダウンジャケットを売り出している。売れ筋のダウンジャケットは大量に販売されるために規模の経済によりコストパフォーマンスがよくなる。
製品カテゴリの中で企業が注力しているモデルを選択することは消費者が賢く買い物をする上でひとつの要因になりうる。
一般的に同カテゴリの製品のラインナップでは全体の商品の平均値近辺に売れ筋商品の値付けをする。
ここでは製品ラインナップの値段についての平均から売れ筋商品を調べた。
内容
データ
データとしてはモンベルのオンラインショップからの製品データを取得した。また売れ筋としてはgoogleによる検索結果件数を利用した。
方法
モンベルのダウンジャケットについて商品ラインナップを調査する。
幾何平均・算術平均を利用してモンベルが注力している商品を明らかにしてみる。ライ ンナップについて幾何平均および算術平均を計算する。この近辺に売れ筋があると仮定し平均に近い前後の2種の商品を選ぶ。
次に商品の人気度を比較し て、選ばれた2種の人気度が高いかを検証する。人気度はgoogleの検索キーワード数を利用する。厳密には売り上げデータが望ましいが、公開されていな い。Googleの検索キーワードは消費者から見ればほしい商品を調べるときに利用し、供給側からすれば売りたい商品のキーワードを増やそうとするので代 用が可能と考えられる。
結果
仮説
幾何平均もしくは算術平均の近辺に売れ筋を置いていると仮説を立てた。
商品ラインナップ
モンベルの商品ラインナップは13種類ある。
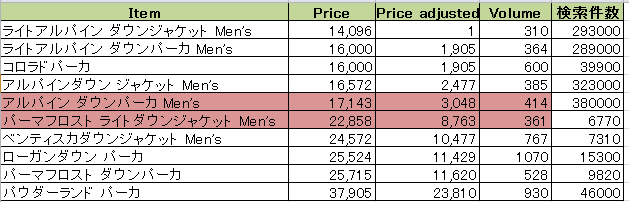
幾何平均および算術平均
幾何平均および算術平均は以下のようになっている。
| 幾何平均 | 20,683 |
| 算術平均 | 21,639 |
幾何平均による結果
幾何平均は20,682である。この値に近い商品はアルパインダウンパーカとパーマフロストライトダウンジャケットとなる。
この2つについて人気度を調べる。アルパインダンパーカは380,000件であり全商品の中でトップとなった。それに対して、パーマフロストライトダウンジャケットは6770件であり、10商品中10位である。このことからモンベルが力を入れている商品はアルパインダウンパーカであると考えられる。同系統の商品でアルパインダウンジャケットがありこちらもほぼ金額としては同一であり、この2種が主力といえる。
商品について累乗近似を行い回帰が可能であるかを検証してみる。
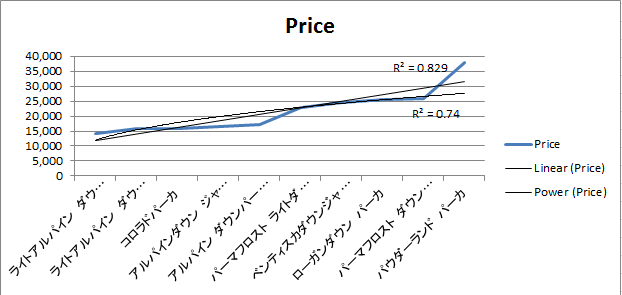
線形回帰の結果累乗近似では0.74となった。幾何平均のプロットをしてみると商品ラインナップの中では平均より下回っていることがわかる。この結果客に対してお得感を与えて、価格面からさらに購入を誘導していると推測できる。
算術平均による結果
算術平均は21,639である。線形近似線の重相関係数は0.829であり、累乗近似線の重相関係数より高い。この値に近い商品は幾何平均と同じでアルパインダウンパーカとパーマフロストライトダウンジャケットとなる。しかし価格としてはパーマフロストライトダウンジャケットに近づいている。
まとめ
売れ筋商品の予測は値付けから可能であることがわかった。値段から売れ筋商品について予測できるために、公開されているオンラインショップのデータが利用できる。
幾何平均と算術平均では大きな違いが見受けられなかった。これは価格帯によると考えられる。しかし重相関係数については異なるために両方での検証は必要と考えられる。
