data可視化ライブラリのseabornではすぐに機械学習を始められるように質が良いデータが用意されている。その中でも最も有名であるirisについてpairplotを使って可視化してみる。
ここでは以下について説明する
- seabornで用意されているデータ
- irisの読み込み方
- seaborn.pairplotで可視化
- カテゴリ別にデータを可視化
seabornで用意されているデータ
seabornで用意されているデータは.get_dataset_names()で取得できる。
print(sns.get_dataset_names()) # ['anscombe', 'attention', 'brain_networks', 'car_crashes', 'diamonds', 'dots', 'exercise', 'flights', 'fmri', 'gammas', 'iris', 'mpg', 'planets', 'tips', 'titanic']
このデータの本体はgithubで公開されている。
irisの読み込み方
irisデータを読み込む。iris.DESCRでそのデータセットの説明が出てくる。
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()
#
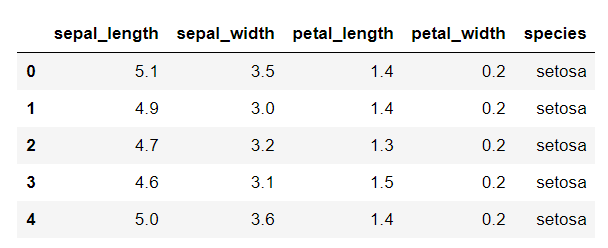
scikit-learnでもirisデータは用意されている。しかし初めてである場合にはseabornのデータセットを使うほうが簡単である。その理由としては、speciesがついているので、すでに正解データがわかる。これにより機械学習のモデルづくりと検証が簡単にできる。2つ目の理由としては読み込むとすぐにDataFrameになっていることである。scikit-learnのデータはndarray型であるためにpandas.DataFrameで変換する必要がある。
seabornでデータを可視化
seabornを利用するとデータの可視化が簡単にできる。
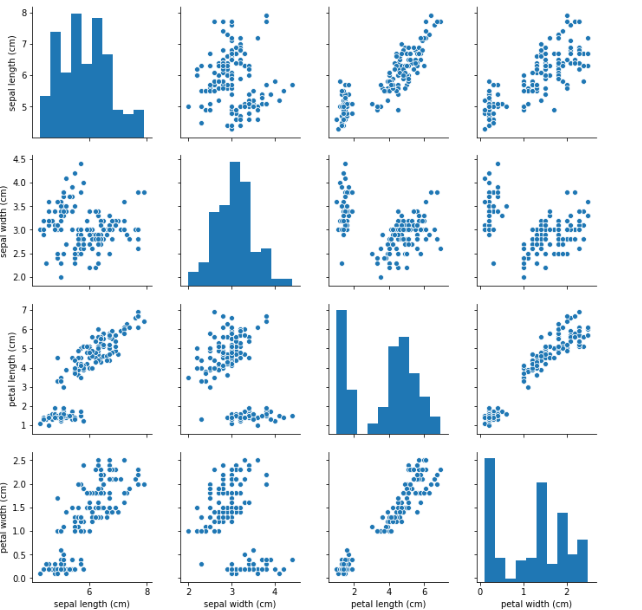
seabornで最も強力なt関数の一つがpairplotをある。この関数にデータを送るとすべてのカラムについてペアで可視化をする。しかも変数の種類により、グラフも変えてくれる。
sns.pairplot(iris)
カテゴリ別にデータを可視化
さてデータを可視化をしてみたがこれだけではデータ分析のために役立つは言い難い。例えば次の散布図を見てみる。
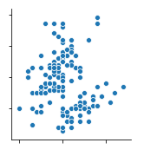
こちらは大きく分けて2つのブロックに分かれている。知りたいにはこのブロックが種類によって分かれているのか、それともランダムかである。
もし種類によって分かれているということであればx軸とy軸の値の関係から、最小二乗法で種類を予測することができる。もちろんすべて総当たりでという方法もあるが、データ量が多い場合にはあらかじめ絞りこみができれば都合がよい。
この時に役に立つのがhueである。
| seaborn.pairplot(data, hue=None, hue_order=None, palette=None, vars=None, x_vars=None, y_vars=None, kind=’scatter’, diag_kind=’auto’, markers=None, height=2.5, aspect=1, dropna=True, plot_kws=None, diag_kws=None, grid_kws=None, size=None) |
hueはデフォルトでは指定されていないのでカテゴリ別にわけずデータを可視化する。いまhueに’species’を指定する。
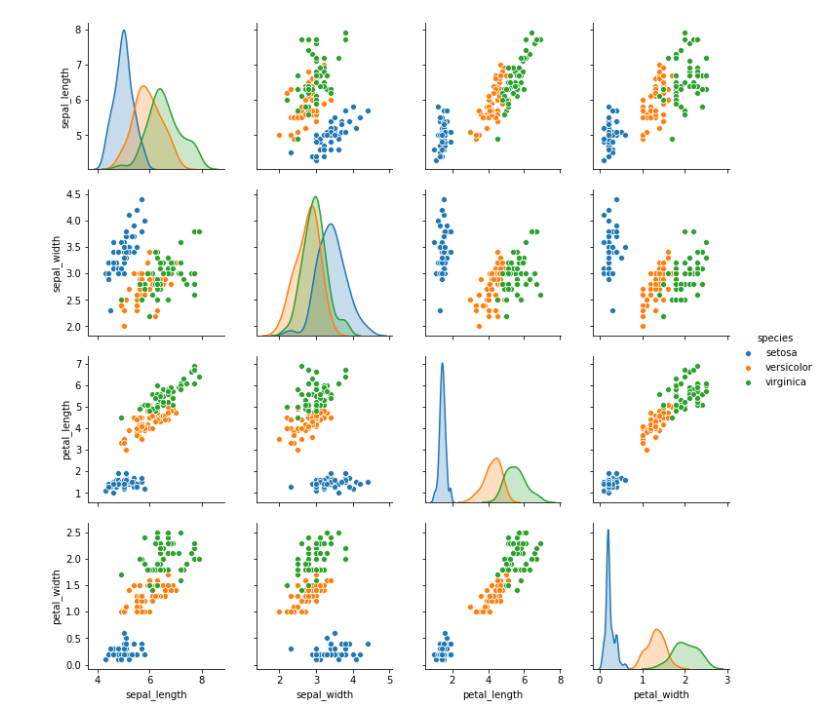
これにより例えばsepal_lengthとsepal_widthを利用すればspeciesを分けられる可能性があることがわかる。
