さて、今回は年齢について検証する。まずこれまでは中央値を使っていたわけだ。これをもともと年齢分布と中央値を使って更新した後の年齢分布を比較する。
import numpy as nm
import pandas as pd
import seaborn as sns
%matplotlib inline
d_train = pd.read_csv('train.csv')
d_train['Age_1'] = d_train['Age']
fig, (axis1,axis2) = plt.subplots(1,2,figsize=(15,4))
axis1.set_title('Original Age')
axis2.set_title('Update Null with Mean')
d_train["Age_1"] = d_train["Age_1"].fillna(29.69911764705882)
d_train['Age'].hist(bins=70, ax=axis2)
d_train['Age_1'].hist(bins=70, ax=axis4)
この結果は以下のようになります。
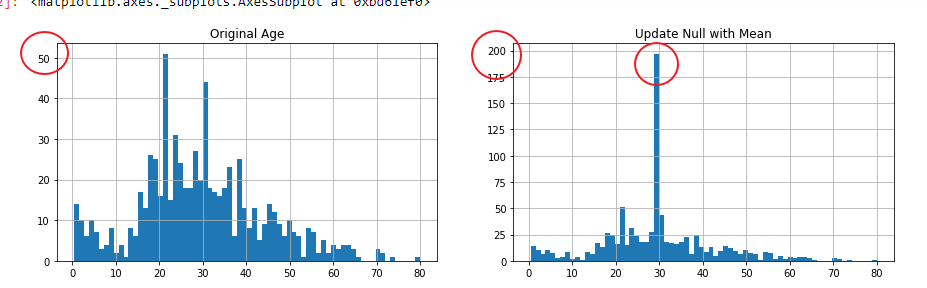
わかりにくいのですが更新前は22歳で最大値が50であったのに対して、更新後は29歳で200になっています。この結果として分布図が極端に変化しています。
明らかに更新した年齢は実体にそぐわないものになっています。
そこでこちらを参考にして他のデータを参考にしてAgeを保管する。
https://ahmedbesbes.com/how-to-score-08134-in-titanic-kaggle-challenge.html
d_train = pd.read_csv('train.csv')
d_train['title'] = d_train['Name'].apply(get_title).map(Title_Dictionary)
d_train['FamilySize'] = d_train['SibSp'] + d_train['Parch'] + 1
d_train_g = d_train_g = d_train.groupby(['Sex','Pclass','title', 'FamilySize'])
d_train_g_m = d_train_g.median()
d_train_g_m.reset_index()[['Sex', 'Pclass', 'title', 'FamilySize', 'Age']]
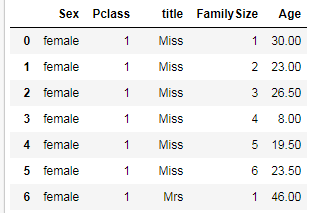
性別、Class, title, FamilySizeにより年齢が全く異なるのがわかる。
次回はこの結果を利用してAgeを補完する。
