さて今回はAgeを補完してから、元の分布と比べてみる。
def fill_age(row):
condition = (
(d_train_g_m['Sex'] == row['Sex']) &
(d_train_g_m['Pclass'] == row['Pclass']) &
(d_train_g_m['title'] == row['title']) &
(d_train_g_m['FamilySize'] == row['FamilySize'])
)
return d_train_g_m[condition]['Age'].values[0]
d_train = pd.read_csv('train.csv')
d_train['title'] = d_train['Name'].apply(get_title).map(Title_Dictionary)
d_train['FamilySize'] = d_train['SibSp'] + d_train['Parch'] + 1
d_train_g = d_train_g = d_train.groupby(['Sex','Pclass','title', 'FamilySize'])
d_train_g_m = d_train_g.median()
d_train_g_m = d_train_g_m.reset_index()[['Sex', 'Pclass', 'title', 'FamilySize', 'Age']]
d_train['Age'] = d_train.apply(lambda row: fill_age(row) if np.isnan(row['Age']) else row['Age'], axis=1)
d_train['Age'].hist(bins=70)
結果としては以下のようになった。
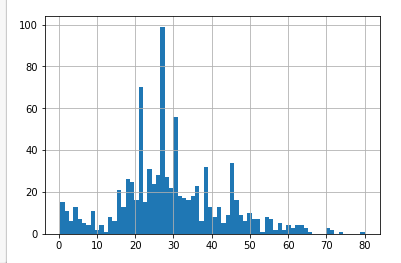
ちなみにオリジナルは以下である。
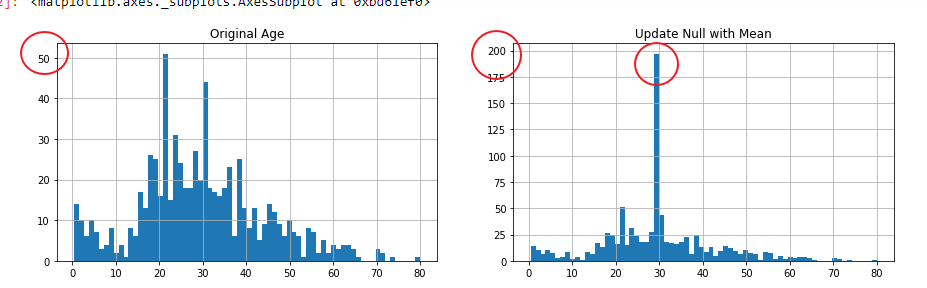
まだ突出したデータがあるがとりあえずは改善されている。この結果を基にして分析をしてみる。
関連するコードだけ記載する
d_train['Age'] = d_train.apply(lambda row: fill_age(row) if np.isnan(row['Age']) else row['Age'], axis=1) d_test['Age'] = d_train.apply(lambda row: fill_age(row) if np.isnan(row['Age']) else row['Age'], axis=1) d_train["Age"] = d_train["Age"].fillna(29.69911764705882) d_test["Age"] = d_test["Age"].fillna(30.272590361445783)
kaggleに提出したが残念ながら結果はいまいちであった。
ツリーを検証すると以下のようになっている。
for name, importance in zip(["Pclass", "Sex", "Age", "Fare", "Embarked", "FamilySize", "title"], dtree.feature_importances_): print(name, importance)
Pclass 0.149357330313 Sex 0.435936591715 Age 0.136292322156 Fare 0.155380673517 Embarked 0.0141969919789 FamilySize 0.0965189783912 title 0.0123171119299
