回帰分析の手順
- データを取得する。
- 回帰分析をする意味があるかを検討する
- 回帰分析のモデルを検討する
- 回帰分析をする
- 回帰分析の結果について考察する
回帰分析のメモ
- 回帰分析では目的変数を説明できる変数を見つける。
- 重回帰分析では特定の目的変数を作る 例) 特定の品物を買う人 = a x コンビニで買う人 + b x 特定の企業に勤める + c
- モデルが適切であるかを常に判断する。 目的変数が2値ならばロジスティック回帰を採用する。
- 多重共線性で変数間の相関が出ていないかを調べる。
- 回帰分析の検証には残差誤差の検定とF検定がある。
- カテゴリ変数は 0 , 1, 2, 3と値をふるのではなく、カテゴリA内水準1, カテゴリA内水準2, カテゴリA内水準3とフィールドを作り 0/1を設定する。
Rによる回帰分析
Rに付属しているデータセットcarsを利用して回帰分析をする。
データの読み込み
carsデータを読み込む。
> data(cars)
carsデータセットについて基本的なチェックをする。
> names(cars) [1] "speed" "dist" > head(cars) speed dist 1 4 2 2 4 10 3 7 4 4 7 22 5 8 16 6 9 10 > summary(cars) speed dist Min. : 4.0 Min. : 2.00 1st Qu.:12.0 1st Qu.: 26.00 Median :15.0 Median : 36.00 Mean :15.4 Mean : 42.98 3rd Qu.:19.0 3rd Qu.: 56.00 Max. :25.0 Max. :120.00
データ検証
cars$speedとcars$distについて回帰式を求める意味があるかを調べる。carsデータセットのspeedとdistについて線形回帰が適当であるかを確認してみる。
> plot(cars$speed, cars$dist)
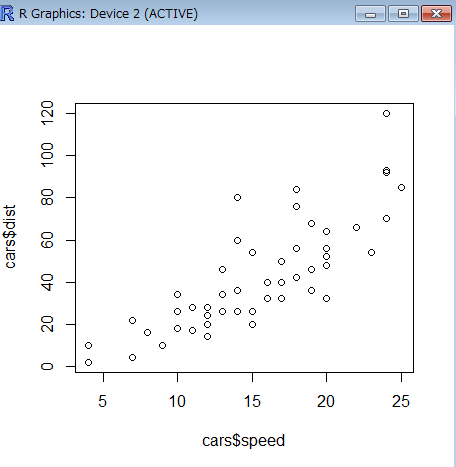
散布図より線形モデルに適合しそうなことがわかる。
データセットについてすべての変数について散布図を取得したい場合にはplot(データセット名)で取得できる。下記はirisデータセットを使った結果である。
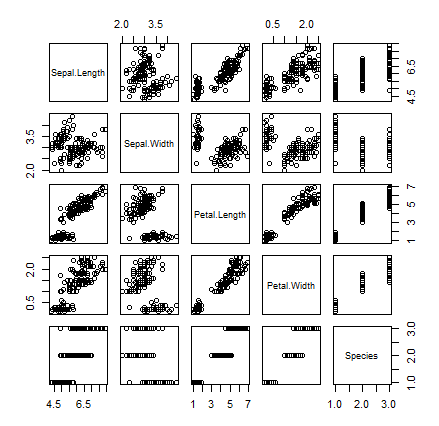
相関係数を求める。Rではcor()関数で取得できる。methodパラメータを指定しなければpearsonの相関係数が得られる。
> cor(cars$speed, cars$dist) [1] 0.8068949 > cor(cars$speed, cars$dist, method="p") [1] 0.8068949
スピアマンの順相関係数を求めたいときにはmethodに”s”もしくは”spearman”を指定する。
> cor(cars$speed, cars$dist, method="s") [1] 0.8303568
相関係数も散布図と同様にしてcor(カラム)ですべての変数間について相関係数を取得できる。
> cor(iris[1:4]) Sepal.Length Sepal.Width Petal.Length Petal.Width Sepal.Length 1.0000000 -0.1175698 0.8717538 0.8179411 Sepal.Width -0.1175698 1.0000000 -0.4284401 -0.3661259 Petal.Length 0.8717538 -0.4284401 1.0000000 0.9628654 Petal.Width 0.8179411 -0.3661259 0.9628654 1.0000000
iris$Speciesが数値以外のデータであるために取り除き、それ以外のカラムについて相関係数を取得している。
次に無相関検定を実施する。
> cor.test(cars$speed, cars$dist) Pearson's product-moment correlation data: cars$speed and cars$dist t = 9.464, df = 48, p-value = 1.49e-12 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: 0.6816422 0.8862036 sample estimates: cor 0.8068949
この結果により以下がわかる。
- t値は9.464
- 自由度は48
- 相関がない場合にt=9.464になる確率は 1.49e-12
- 対立仮説は”相関係数は0に等しくない”
- 相関係数の95%の信頼空間は0.6816422~0.8862036になる。
- サンプルから求められた相関係数は0.8068949
よって2つの変数cars$speedとcars$distには相関がありそうだとわかり回帰式を求める意味がある。
検定結果について詳細に見る
検定結果について内容を見る場合には以下の手順で進める。
検定結果について含まれるデータを確認する。
> names(cars.cortest) [1] "statistic" "parameter" "p.value" "estimate" "null.value" [6] "alternative" "method" "data.name" "conf.int"
個別のデータについて含まれる値を確認すr。
> cars.cortest$conf.int [1] 0.6816422 0.8862036 attr(,"conf.level") [1] 0.9
属性について取得したい場合にはattr()を使う。
> attr(cars.cortest$conf.int, "conf.level") [1] 0.95
回帰式を求める
Rでは回帰式はlmで求める。
> cars.lm <- lm(formula=cars$dist ~ cars$speed, data = cars) > cars.lm Call:lm(formula = cars$dist ~ cars$speed, data = cars) Coefficients:(Intercept) cars$speed -17.579 3.932
summaryを使って詳細な結果を取得する。
> summary(cars.lm) Call: lm(formula = cars$dist ~ cars$speed, data = cars) Residuals: Min 1Q Median 3Q Max -29.069 -9.525 -2.272 9.215 43.201 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -17.5791 6.7584 -2.601 0.0123 * cars$speed 3.9324 0.4155 9.464 1.49e-12 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 15.38 on 48 degrees of freedom Multiple R-squared: 0.6511, Adjusted R-squared: 0.6438 F-statistic: 89.57 on 1 and 48 DF, p-value: 1.49e-12
回帰式とデータをプロットする
> plot(cars) > abline(cars.lm, lwd=2, col="blue")
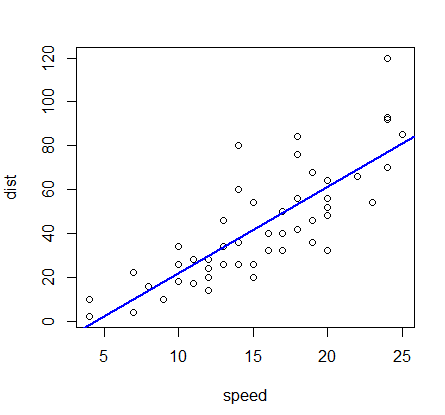
直線の引き方は下記も使える。
lines(cars$speed, cars.lm$fitted, col="red", lwd=3)
回帰分析の結果を考察する
回帰式
回帰式は 距離 = 3.9324 x スピード -17.5791と推定された。
決定係数
R^2=0.6438であるから、距離の分散の64%はスピードで説明されている。36%については残差で説明されている。
t検定
切片の推定値 -17.5791であり、帰無仮説 切片=0としたときに検定結果はP=0.0123となり棄却される。
傾きの推定値は3.9324であり、帰無仮説 傾き=0としたときに検定結果はP=1.49e-12となり棄却される。
回帰分析の検証
予測値、残差表
予測値および残差についてまとめた表を作成する。
> report <- data.frame(cars$speed, cars$dist, predict(cars.lm), residuals(cars.lm)) > report cars.speed cars.dist predict.cars.lm. residuals.cars.lm. 1 4 2 -1.849460 3.849460 2 4 10 -1.849460 11.849460 3 7 4 9.947766 -5.947766 4 7 22 9.947766 12.052234 5 8 16 13.880175 2.119825 6 9 10 17.812584 -7.812584 7 10 18 21.744993 -3.744993 8 10 26 21.744993 4.255007 9 10 34 21.744993 12.255007 10 11 17 25.677401 -8.677401
残差パターン
残差についてパターンがないかを確認するために視覚化する。残差にパターンがある場合にはより最適な説明変数を見つける、あるいは重回帰分析に進む必要がる。
plot(cars$speed, residuals(cars.lm)) abline(c(0,0), col="red", lwd=3)
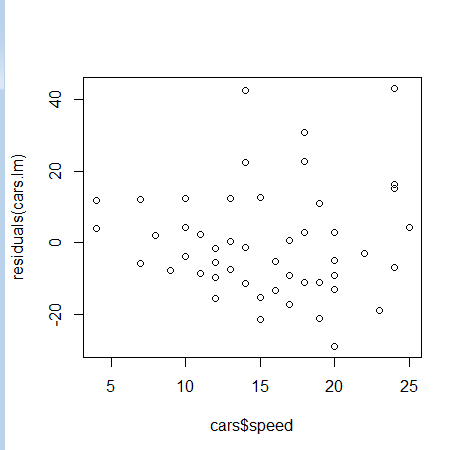
残差はスピードが速くなると大きくなることがわかる。よってスピードが遅いとモデルにフィットするが速い場合には他の要素により距離にばらつきが出ることがわかる。例とえば、タイヤの質、テスト当日の天候・気温、ドライバーの質などが考えられる。
モデルの実測値に対するフィット
モデルのフィットを視覚化する為に測定値と予測値でプロットする。
> plot(cars$dist, predict(cars.lm)) > abline(a=0, b=1)
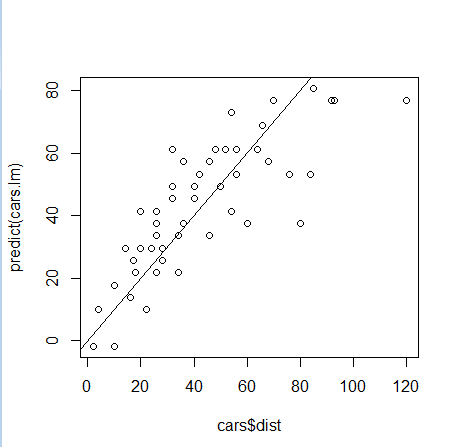
実測値とモデルがフィットしていればy=x上に点が集まるはずである。しかし距離が伸びるほどy=xから離れている標本が多くなるのがわかる。
残差診断図
残差診断図を分析する。残差診断図を利用することで残差に求められる、正当性、等分散性、線形性が明らかになる。独立性は単回帰分析では関係ない。
> par(mfrow=c(2,2)) > plot(cars.lm)
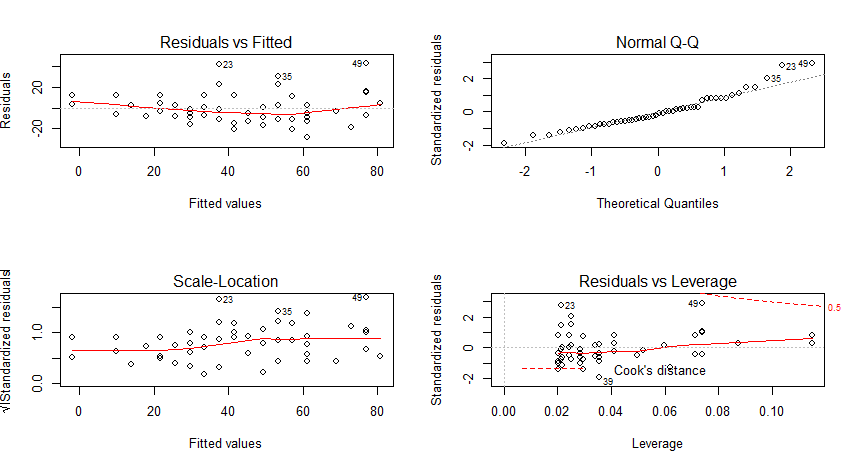
1. 残差と予測値の対比(残差の線形性)
この表では残差と予測値を対比している。予測値が40より大きくなると40以下に比べて大きな残差が出てくることがわかる。ただし大きな残差が3つのグループに分かれていて(予測値40, 60, 80)、個数ととしては最大で4のために何らかの共通性がないかを調べる必要がある。
2. 残差のQQプロット(残差の正規性)
残差についてQQプロットを作成する。QQプロットではデータが正規分布したがっていると直線状に並ぶ。ほぼ直線状に並んでいるために残差は正規分布に従っていると考えられる。よって特定要因が残差に影響していることは考えにくい。
3. 標準化した残差の平方根(残差の等分散性)
残差の変動状況を見る。やはり予測値40, 60, 80で変動幅が大きくなっていることがわかる。
4.テコ比とクックの距離
テコ比が大きいデータはモデルに対して大きな影響を与える。いいかえるとその値を取り除くことでモデルに大きな変化が生じることになる。モデルを構築するにあたり、データが同じモデルに属するのであればテコ比はほぼ同じになる。明らかに大きいテコ比をもつデータは外れ値である可能性が高いために検証して、必要であれば取り除く。
クックの距離が0.5を超えると該当データのモデルへの影響力が大きくなる。
はずれ値についての評価
残差 2SDもしくは3SD
クックの距離
てこ比
マハラノビス距離
推定
母集団について95%の信頼区間を視覚化する
回帰分析で得られたモデルは推定である。ここから母集団について95%の信頼区間をもとめ視覚化する。
母集団の信頼区間はpredict()関数のパラメータintervalに”confidence”を設定する。
cars.confidence <- predict(cars.lm, interval="confidence")
cars.confidenceの内容について確認をしてみる。
> head(cars.confidence) fit lwr upr 1 -1.849460 -12.329543 8.630624 2 -1.849460 -12.329543 8.630624 3 9.947766 1.678977 18.216556 4 9.947766 1.678977 18.216556 5 13.880175 6.307527 21.452823 6 17.812584 10.905120 24.720047
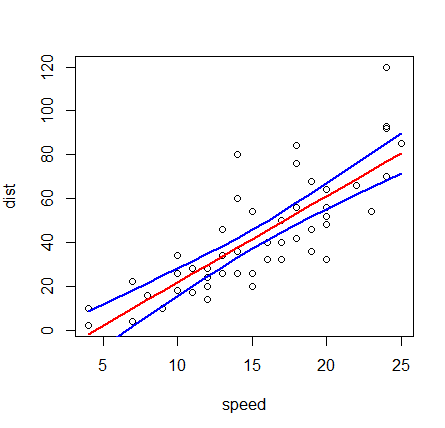
モデル、信頼区間、観測したデータをプロットする。
> plot(cars) > lines(cars$speed, cars.confidence[,2], lwd=2, col="blue") > lines(cars$speed, cars.confidence[,3], lwd=2, col="blue") > lines(cars$speed, cars.confidence[,1], lwd=2, col="red")
予測区間
標本取得を繰り返し回帰分析を実施した場合の予測区間についても視覚化する。
> cars.prediction <- predict(cars.lm, interval="prediction") 警告メッセージ: In predict.lm(cars.lm, interval = "prediction") : 現在のデータによる予測は未来の応答値を参照しています > head(cars.prediction) fit lwr upr 1 -1.849460 -34.49984 30.80092 2 -1.849460 -34.49984 30.80092 3 9.947766 -22.06142 41.95696 4 9.947766 -22.06142 41.95696 5 13.880175 -17.95629 45.71664 6 17.812584 -13.87225 49.49741 > plot(cars) > lines(cars$speed, cars.prediction[,2], lwd=2, col="blue") > lines(cars$speed, cars.prediction[,3], lwd=2, col="blue") > lines(cars$speed, cars.prediction[,1], lwd=2, col="red")
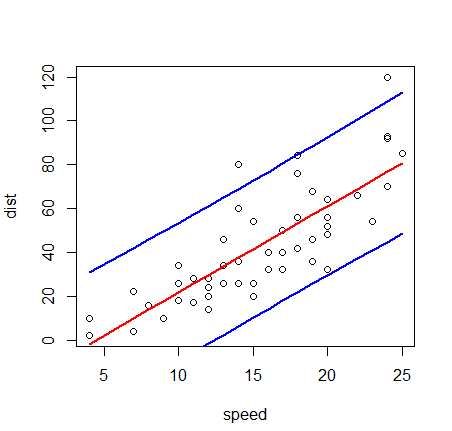
予測区間は信頼区間の誤差に加えて、標本抽出時の揺らぎがあるために信頼区間より広くなっていることがわかる。
見せかけの回帰について検証
単位根検定
共和根
撹乱項の独立性の検定(自己相関があるか) – DW比
自己相関がある場合の対応 – コクランオーカット法
分散の不均一性
多重共線性
説明変数が質的変数である場合の回帰分析
重回帰分析
非線形回帰分析
ロジット、成長曲線、対数線形モデル、GROWTH関数
