Rでのランダムデータ作成 – 上級編にコメントをいただいたので調べてみた。結果を対比するためにプロットも入れた。
まずデータフレームを使う方法が以下である。
lm1 <- lm(galton$child ~ galton$parent)
// galtonについて回帰分析を実行
newGalton <- data.frame(parent=rep(NA,1e3),child=rep(NA,1e3))
// dataframeの箱を作りparentとchildを保管する。このときNAでとりあえず値を設定する。
newGalton$parent <- rnorm(1e3,mean=mean(galton$parent),sd=sd(galton$parent))
// parentにrnormでランダム値を設定する。
newGalton$child <- lm1$coeff[1] + lm1$coeff[2]*newGalton$parent + rnorm(1e3,sd=sd(lm1$residuals))
// 回帰分析の結果を利用してchildを計算する。
plot(newGalton$parent, newGalton$child, col="red", )
par(new=T)
plot(galton$parent, galton$child, col="black")
abline(lm1, col="blue")
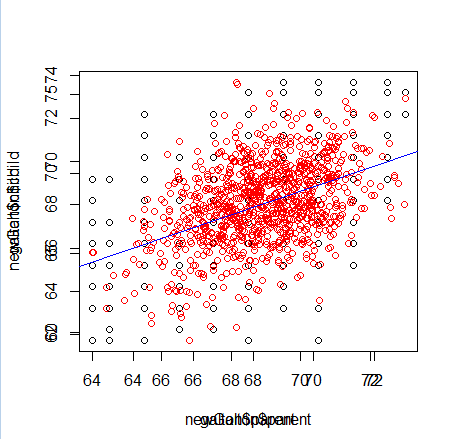
次に以下のようにnewGalton作成部分を変更してみるとnewGaltonの型が変更されたというメッセージが出る。
> newGalton <- rnorm(1e1,mean=mean(galton$parent),sd=sd(galton$parent)) > newGalton$child <- lm1$coeff[1] + lm1$coeff[2]*newGalton + rnorm(1e1,sd=sd(lm1$residuals)) 警告メッセージ: In newGalton$child <- lm1$coeff[1] + lm1$coeff[2] * newGalton + : 左辺をリストに変換しました
型変換がどのように起きたのかを確認してみる。
> newGalton <- rnorm(1e1,mean=mean(galton$parent),sd=sd(galton$parent)) > class(newGalton) [1] "numeric" > newGalton$child <- lm1$coeff[1] + lm1$coeff[2]*newGalton + rnorm(1e1,sd=sd(lm1$residuals)) 警告メッセージ: In newGalton$child <- lm1$coeff[1] + lm1$coeff[2] * newGalton + : 左辺をリストに変換しました
rnormの結果はベクトルで戻されている。次にchild要素をnewGaltonに挿入しようとすると自動的にlistに変わることがわかった。
ここでプロットをするとエラーが出てくる。
> plot(newGalton, newGalton$child, col="red") 以下にエラー xy.coords(x, y, xlabel, ylabel, log) : 'x' and 'y' lengths differ
このエラーによるとnewGaltonとnewGalton$childの長さが異なるといっている。長さを確認してみる。
> length(newGalton) [1] 1001 > length(newGalton$child) [1] 1000
newGaltonがnewGalton$childより一つ大きくなっている。この要素を確認してみると以下のようになっていることがわかった。つまりnewGaltonのparents要素は1000個あるがその後にchildのリストがくっついて合計で1001になっている。
> tail(newGalton) [[1]] [1] 65.12567 [[2]] [1] 69.11315 [[3]] [1] 65.49789 [[4]] [1] 70.53813 [[5]] [1] 65.3993 $child [1] 67.66462 69.89059 68.45603 68.64014 69.47576 65.69980 62.11066
では最初からnewGaltonがリストになっていればよいので、以下のように修正した。
lm1 <- lm(galton$child ~ galton$parent) newGalton$parent <- rnorm(1e3,mean=mean(galton$parent),sd=sd(galton$parent)) newGalton$child <- lm1$coeff[1] + lm1$coeff[2]*newGalton$parent + rnorm(1e3,sd=sd(lm1$residuals)
これで正しくプロットされた。
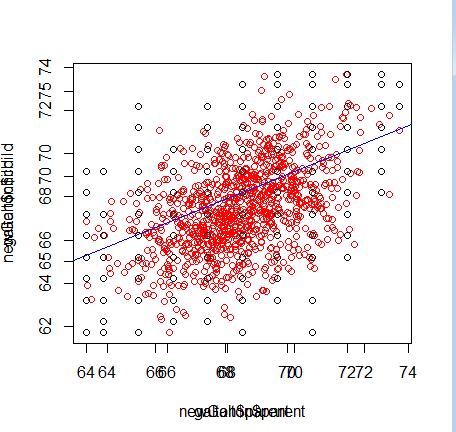
次にpredict()について確認をしてみた。
predict()を利用してnewGalton$childを計算してみると以下のようにエラーになる。
> newGalton$child <- predict(lm1, newGalton$parent) 以下にエラー eval(predvars, data, env) : 数値の 'envir' 引数の長さが1ではありません
調べたところpredictに引き渡すデータはデータフレームのようだ。
> newGalton$child <- predict(lm1, data.frame(newGalton$parent)) 警告メッセージ: 'newdata' は 1000 個の行を持ちますが、見付かった変数は 928 の行数を持ちます:
計算はできたがなぜがデータは928個になってしまった。
> length(newGalton$child) [1] 928
ちょっとよくわからないのでここまで。

galton データは,HistData の Galton データでしょうか?
プログラムにおいて,細かな誤りが重積し,わかりにくいエラーを発生させていますね。
まず,newGalton と newGalton$child の違いについて混乱がありますね。
newGalton <- rnorm(1e1,mean=mean(galton$parent),sd=sd(galton$parent))
で作られる newGalton は要素数 1e1 = 10 のベクトルです。
newGalton$child <- lm1$coeff[1] + lm1$coeff[2]*newGalton + rnorm(1e1,sd=sd(lm1$residuals))
の段階で,代入された後の左辺の newGalton はリストになり,その要素 child つまり newGalton$child に右辺値を代入することになります。右辺のベクトルの newGalton の演算もベクトルですから,ベクトルをリストに代入しようとしたので変換が起きるわけです。
この時点で,
plot(newGalton, newGalton$child, col="red")
をやると,横軸に使用しようとしている newGalton は,もはやベクトルではありません。10個の要素を持つリストと10個の要素を持つベクトルで plot しようとするのでおかしなことが起きます。length(newGalton) とlength(newGalton$child) を調べるのもよいですが,class を見てみるとか,head で内容を書き出してみると思い違いに気づくことができるでしょう。
predict(実際には predict.lm が使われる) を使うときの newdata の使い方もよく確認する必要があります。独立変数のみを含むデータフレームを与えます。
以下が,あなたがやろうとしていたことを行うプログラムです。
library(HistData)
data(Galton)
lm1 <- lm(child ~ parent, data=Galton)
parent.data <- rnorm(1e3,mean=mean(Galton$parent),sd=sd(Galton$parent))
new.data <- data.frame(parent=parent.data)
child.data <- predict(lm1, newdata=new.data)