tracertを繰り返し実行した結果を分析し、経路上のホストについてどの程度時間がかかっているかを分析してみる。
tracertの結果は以下のように取得される。
$ tracert www.google.com www.google.com [173.194.70.105] へのルートをトレースしています 経由するホップ数は最大 30 です: 1 68 ms 68 ms 3 ms nn.nn.nn.nn 2 <1 ms <1 ms <1 ms nn.nn.nn.nn 3 3 ms 1 ms 1 ms nn.nn.nn.nn
tracertの繰り返し実行は以下のスクリプトで取得する。
set /a j=1 :start1 if %j% GTR 2000 goto last1 tracert nn.nn.nn.nn >> tr.log timeout /T set /a j+=1 timeout 60 /nobreak >nul goto start1 :last1
目的はホップごとに最小・最大・平均値のRTT値を求める。取得したデータはtracertの結果であるので、エクセルに取り込み必要な処理をしてから、Rに取り込み分析をする。
エクセルで実行した作業は以下となる。
- IDをふり、作業中に気になったデータを把握できるようにする。
- 試行回数を明らかにする。これはtracert開始時の”Tracing route to”コメントと終了時の”Trace complete.”の出現回数をカウントした。
- コメント行を削除する。
- ms単位のカラムを削除する
- RTTについて数値変換 “<“がついている場合には削除する。
- fixed lenghtで読み込み、おかしくなったレコードについて修正
この結果以下のようなデータを取得できた。
| ID | Hop | T1 | T2 | T3 | Router |
| 4 | 1 | 2 | 2 | 2 | a |
| 8 | 1 | 2 | 3 | 2 | a |
| 28 | 2 | 3 | 2 | 2 | b |
| 48 | 2 | 2 | 5 | 6 | b |
| 68 | 3 | 2 | 2 | 3 | c |
| 88 | 3 | 2 | 2 | 2 | c |
| 108 | 4 | 4 | 2 | 2 | d |
| 128 | 4 | 2 | 2 | 2 | d |
| 148 | 4 | 2 | 2 | 2 | d |
| 168 | 4 | 2 | 2 | 2 | d |
| 188 | 5 | 2 | 2 | 2 | e |
| 208 | 5 | 2 | 2 | 2 | e |
| 228 | 5 | 2 | 2 | 2 | e |
このデータをRに読み込み、分析をする。
# データを読み込みカラムを設定後一部確認
setwd("/RStudy/20140609_tr")
tr <- read.table("tr_analysis01.csv", header=T, sep=",")
names(tr) <- c("id", "hop", "t1", "t2", "t3", "router")
head(tr)
Rに読み込まれたデータは以下のようになっている。
> tr id hop t1 t2 t3 router 1 4 1 2 2 2 a 2 8 1 2 3 2 a 3 28 2 3 2 2 b 4 48 2 2 5 6 b 5 68 3 2 2 3 c 6 88 3 2 2 2 c 7 108 4 4 2 2 d 8 128 4 2 2 2 d 9 148 4 2 2 2 d 10 168 4 2 2 2 d 11 188 5 2 2 2 e 12 208 5 2 2 2 e 13 228 5 2 2 2 e
hopはファクタにしておく。このとき順番に並べておき、レポート作成時にtracertのhop番号でソートされるようにしておく。
# hopのfactorを確認する。
levels(factor(tr$hop))
# hopファクタは上の結果に基づいて設定する。
tr$hop <- factor(tr$hop, levels=c("1","2","3","4","5"))
levels(tr$hop)
summaryで確認してみる。
> summary(tr) id hop t1 t2 t3 router Min. : 4.0 1:2 Min. :2.000 Min. :2.000 Min. :2.000 a:2 1st Qu.: 48.0 2:2 1st Qu.:2.000 1st Qu.:2.000 1st Qu.:2.000 b:2 Median :108.0 3:2 Median :2.000 Median :2.000 Median :2.000 c:2 Mean :109.2 4:4 Mean :2.231 Mean :2.308 Mean :2.385 d:4 3rd Qu.:168.0 5:3 3rd Qu.:2.000 3rd Qu.:2.000 3rd Qu.:2.000 e:3 Max. :228.0 Max. :4.000 Max. :5.000 Max. :6.000
hop別にサブセットする。
tr.list <- split(tr, tr$hop)
サブセットしたデータは以下のようになっている。
> tr.list $a id hop t1 t2 t3 router 1 4 1 2 2 2 a 2 8 1 2 3 2 a
router名のテーブルを作成しておく。
> router_name <- tr[!duplicated(tr$hop),] > router_name id hop t1 t2 t3 router 1 4 1 2 2 2 a 3 28 2 3 2 2 b 5 68 3 2 2 3 c 7 108 4 4 2 2 d 11 188 5 2 2 2 e
このデータはrouter = aのテスト結果である。集計するためにはサブセットごとにt1~t3でベクトルを作りたい。sapplyで要素別にベクトルを作るために以下の関数を定義する。
crtvec <- function(x){
as.numeric(as.vector(as.matrix(x)[,c(-1,-2,-6)]))
}
router別要素にベクトルを作成する。
tr.result <- sapply(tr.list, crtvec)
以下のようにルータ別テスト結果のベクトルが作成された。
> tr.result $a [1] 2 2 2 3 2 2 $b [1] 3 2 2 5 2 6
データを分析する。
sapply(tr.result, summary) boxplot(tr.result,names=router_name$router[1:5])
> sapply(tr.result, summary) 1 2 3 4 5 Min. 2.000 2.000 2.000 2.000 2 1st Qu. 2.000 2.000 2.000 2.000 2 Median 2.000 2.500 2.000 2.000 2 Mean 2.167 3.333 2.167 2.167 2 3rd Qu. 2.000 4.500 2.000 2.000 2 Max. 3.000 6.000 3.000 4.000 2
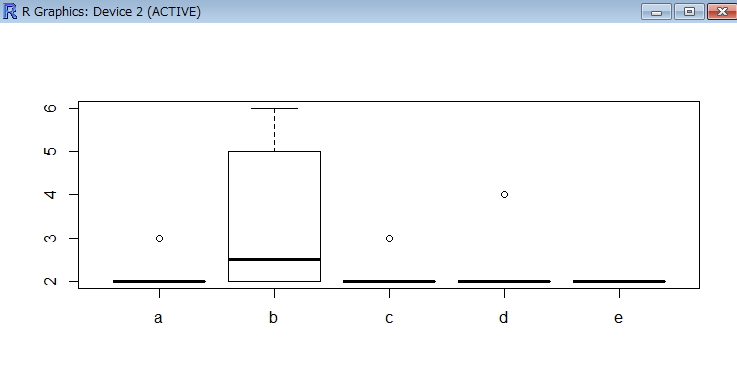
本番データを使うとrouter名が長すぎてx軸のラベルが表示されなかった。下記のようにラベルを垂直にすることで対応した。
require(grDevices) par(mar=c(8.1,4.1,4.1,2.1)) boxplot(tr.result, cex.axis=0.8, las=2, mar=c(2,2,2,2),names=router_name$router[1:5])
ラベルのマージンを変えようとしてmarパラメータを設定したがこちらはうまくいかなかった。
