タイタニックデータでEDAを実施する。
まずはライブラリの読み込み
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline
初期化
sns.set_style('whitegrid')
データを読み込む
d_train = pd.read_csv('titanic_train.csv')
基本情報の取得
d_train.head() d_train.describe()
d_train.info() ' RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): PassengerId 891 non-null int64 Survived 891 non-null int64 Pclass 891 non-null int64 Name 891 non-null object Sex 891 non-null object Age 714 non-null float64 SibSp 891 non-null int64 Parch 891 non-null int64 Ticket 891 non-null object Fare 891 non-null float64 Cabin 204 non-null object Embarked 889 non-null object dtypes: float64(2), int64(5), object(5)
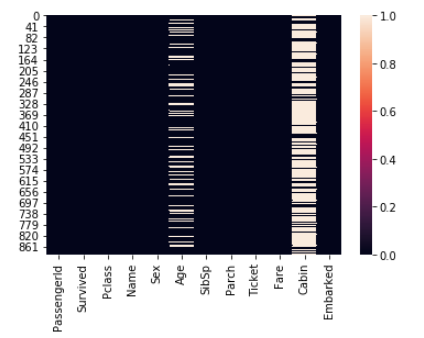
欠落データの取得
sns.heatmap(d_train.isnull())
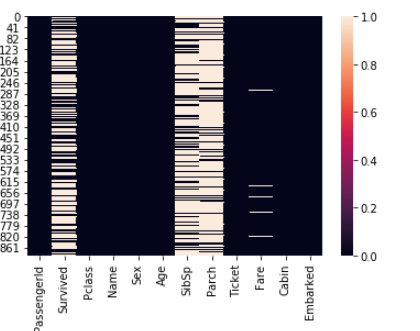
sns.heatmap(d_train == 0)
ユニーク値の件数
d_train.nunique() ' PassengerId 891 Survived 2 Pclass 3 Name 891 Sex 2 Age 88 SibSp 7 Parch 7 Ticket 681 Fare 248 Cabin 147 Embarked 3
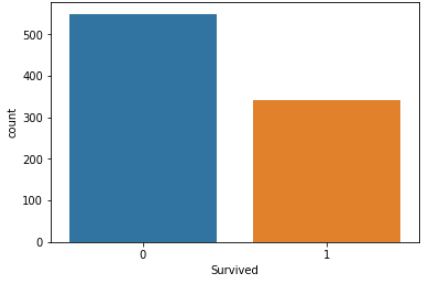
目的変数である生存フラグについて内訳を調べる
sns.countplot(x='Survived', data=d_train)
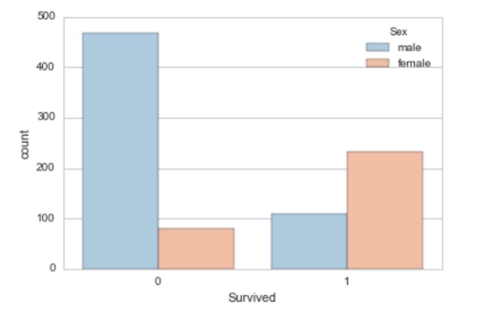
ユニーク値が少ないPClass, Sex, Embarkedで内訳をみてみる。
sns.countplot(x='Survived', hue='Sex', data=d_train)
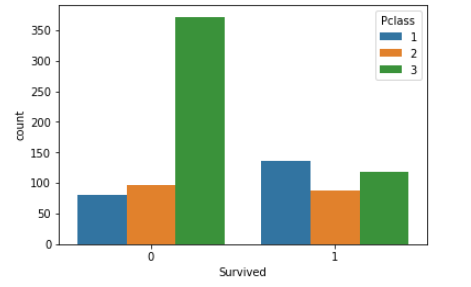
sns.countplot(x='Survived', hue='PClass', data=d_train)
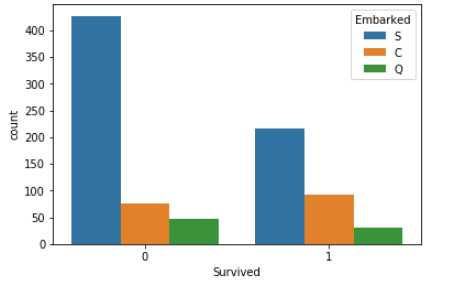
sns.countplot(x='Survived', hue='Embarked', data=d_train)
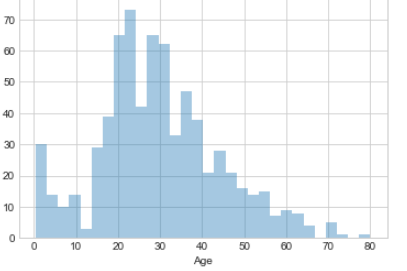
連続尺度についてグラフ表示
sns.distplot(d_train['Age'].dropna(),kde=False, bins=30)
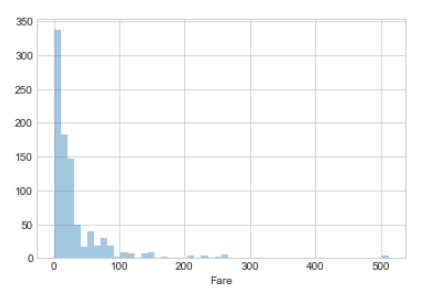
sns.distplot(d_train['Fare'].dropna(),kde=False )
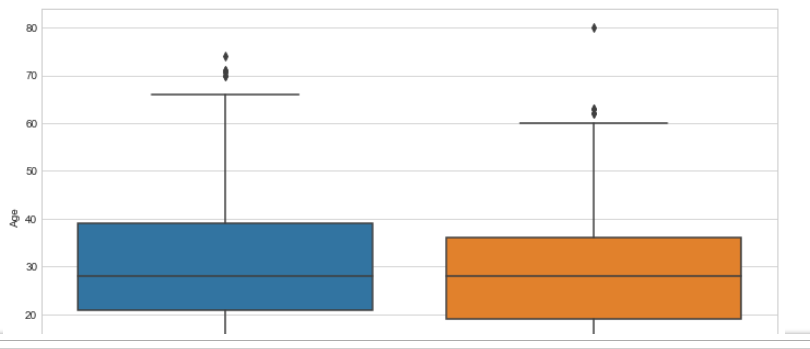
生存フラグについて連続尺度である従属変数により違いがあるか見てみる。
plt.figure(figsize=(12, 7)) sns.boxplot(x='Survied',y='Age',data=d_train)
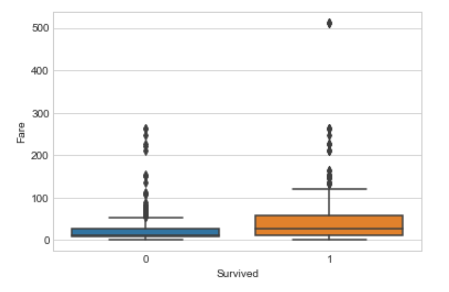
plt.figure(figsize=(12, 7)) sns.boxplot(x='Survied',y='Fare',data=d_train)
データ間の関連を調べる
jointplot
